Java多线程
进程
进程有哪些状态?
就绪状态(Ready):某些进程“万事俱备”(必要资源),只差CPU。(就绪队列)
执行状态(Runing):某进程占有CPU并在CPU上执行其程序。
阻塞状态(Blocked):某些进程由于某种原因不能继续运行下去(如 请求I/O)⽽暂时停⽌运⾏,这时,即使给它 CPU 控制权,它也⽆法运⾏;(多个等待队列)
创建状态(new):进程正在被创建时的状态;
结束状态(Exit):进程正在从系统中消失时的状态;
三种状态随着执行和条件的变化而发生转换:
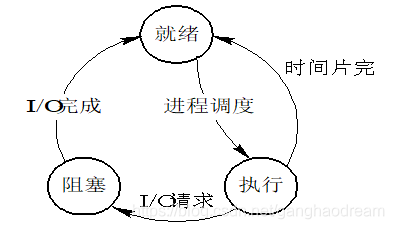
1)就绪→执行:
对就绪状态的进程,当进程调度程序按一种选定的策略从中选中一个就绪进程,为之分配了处理机后,该进程便由就绪状态变为执行状态;
2)执行→阻塞:
正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态。
如:
3)阻塞→就绪:
处于阻塞状态的进程,在其等待的事件已经完成,如输入/输出完成,资源得到满足或错误处理完毕时,处于等待状态的进程并不马上转入执行状态,而是先转入就绪状态,然后再由系统进程调度程序在适当的时候将该进程转为执行状态;
4)执行→就绪:
正在执行的进程,因时间片用完而被暂停执行,或在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行而被迫让出处理机时,该进程便由执行状态转变为就绪状态。
进程间通信有哪些方式?
管道、信号、消息队列、共享内存、信号量和套接字。
进程和线程
说说进程和线程
进程就比如我们在电脑上启动的一个个应用,比如我们启动一个浏览器,就会启动了一个浏览器进程。进程是操作系统资源分配的最小单位,它包括了程序、数据和进程控制块等。
线程就比如我们在 Java 程序中启动的一个 main 线程,一个进程至少会有一个线程。我们也可以启动多个线程。线程是 CPU 分配资源的基本单位。
线程是进程当中的⼀条执⾏流程。
同⼀个进程内多个线程之间可以共享代码段、数据段、打开的⽂件等资源,但每个线程各⾃都有⼀套独⽴的程序计数器和栈,这样可以确保线程的控制流是相对独⽴的。
java虚拟机中,一个进程中可以有多个线程,多个线程共用进程的堆和方法区,但是每个线程都会有自己的程序计数器和栈。
线程与进程的⽐较如下:
调度:进程是资源(包括内存、打开的⽂件等)分配的单位,线程是 CPU 调度的单位;
资源:进程拥有⼀个完整的资源平台,⽽线程只独享必不可少的资源,如寄存器和栈;
状态:线程同样具有就绪、阻塞、执⾏三种基本状态,同样具有状态之间的转换关系;
系统开销:创建或撤销进程时的开销 所付出的开销显著大于在创建或撤销线程时的开销,进程切换的开销也远大于线程切换的开销。因为创建或撤销进程时,系统都要为之分配或回收系统资源,如内存空间,I/O 设备等。
协程(Coroutine)是一种比线程更轻量级的存在。在许多编程语言中,协程是用户态的调度单位,它们可以在单线程中实现并发。协程通过程序员显式调用来切换,而不是由操作系统进行调度。协程主要用于处理异步任务,具有较高的效率。
线程
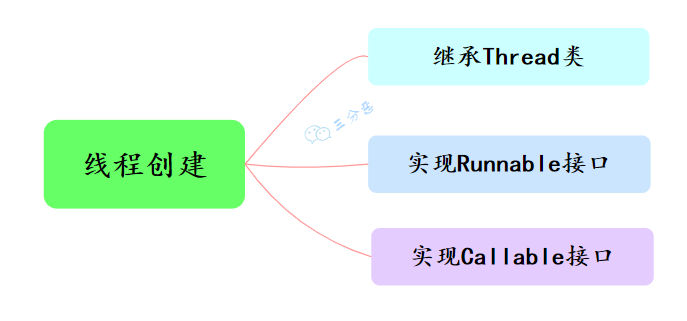
线程有几种创建方式?
- 继承 Thread 类,重写 run()方法,创建对象,调用 start()方法启动线程。这种方法的缺点是,由于 Java 不支持多重继承,所以如果类已经继承了另一个类,就不能使用这种方法了。
class ThreadTask extends Thread {
public void run() {
}
public static void main(String[] args) {
ThreadTask task = new ThreadTask();
task.start();
}
}- 实现 Runnable 接口,重写 run() 方法,然后创建 Thread 对象,将实现 Runnable 接口的对象作为参数传递给 Thread 对象,调用 start() 方法启动线程。
class RunnableTask implements Runnable {
public void run() {
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
Thread thread = new Thread(task);
thread.start();
}
}- 实现 Callable 接口,重写 call() 方法,然后创建 FutureTask 对象,参数为 Callable 对象;紧接着创建 Thread 对象,参数为 FutureTask 对象,调用 start() 方法启动线程。这种方式可以通过 FutureTask 获取任务执行的返回值
class CallableTask implements Callable<String> {
public String call() {
return ...;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallableTask task = new CallableTask();
FutureTask<String> futureTask = new FutureTask<>(task);
Thread thread = new Thread(futureTask);
thread.start();
System.out.println(futureTask.get());
}
}
开发中优先选择实现Runnable接口的方式
原因:
(1)实现的方式没有类的单继承性的局限性
(2)实现的方式更适合来处理多个线程有共享数据的情况
相同点:两种方式都需要重写run(), 将线程要执行的逻辑声明在run()中
不直接调用 run()方法
JVM 执行start 方法,会先创建一条线程,由创建出来的新线程去执行 thread 的 run 方法,这才起到多线程的效果。如果直接调用 Thread 的 run()方法,那么 run 方法还是运行在主线程中,相当于顺序执行,就起不到多线程的效果。
线程有哪些常用的调度方法?
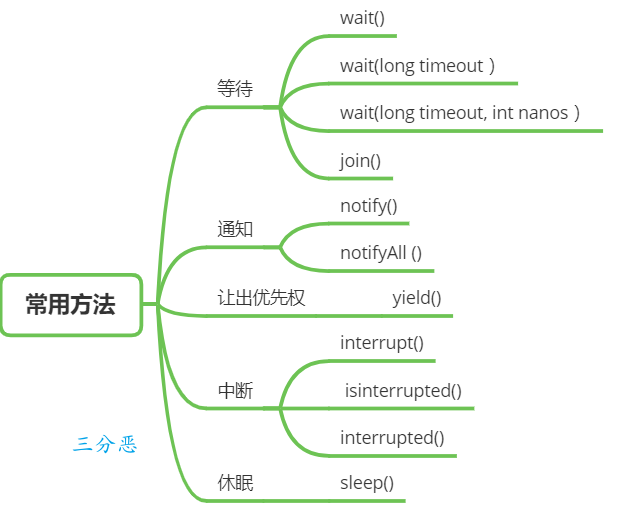
请说说 sleep 和 wait 的区别
①、所属类不同
sleep 是让当前线程休眠,不涉及对象类,也不需要获取对象的锁,属于 Thread 类的方法;
wait 是让获得对象锁的线程实现等待,前提要获得对象的锁,属于 Object 类的方法。
②、锁行为不同
当线程执行 sleep 方法时,它不会释放任何锁。
当线程执行 wait 方法时,它会释放它持有的那个对象的锁,这使得其他线程可以有机会获取该对象的锁。
③、使用条件不同
sleep() 方法可以在任何地方被调用。
调用 wait() 方法的前提是当前线程必须持有对象的锁。否则会抛出 IllegalMonitorStateException 异常。、
④、唤醒方式不同
sleep() 方法在指定的时间过后,线程会自动唤醒继续执行。
wait() 方法需要依靠 notify()、notifyAll() 方法或者 wait() 方法中指定的等待时间到期来唤醒线程。
Java线程状态
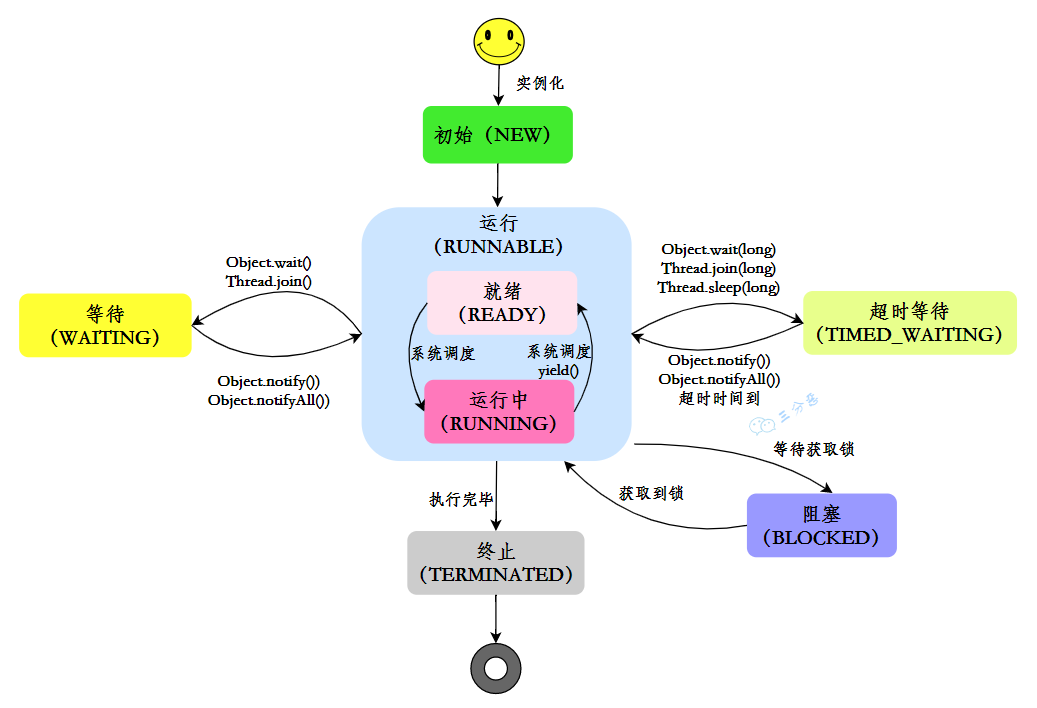
线程上下文切换
CPU 给每个线程分配一个时间片,线程在时间片内占用 CPU 执行任务。当线程使用完时间片后,就会处于就绪状态并让出 CPU 让其他线程占用,这就是上下文切换
violite关键字
在 Java 中,volatile 关键字用于修饰变量,确保多个线程对该变量的可见性和有序性。它常用于多线程编程中解决线程间共享变量的可见性问题。
- 可见性
在多线程环境下,普通变量的修改有可能会被保存在线程的本地缓存中(CPU 寄存器、CPU 缓存),而不会立即更新到主内存中。其他线程读取时,可能读取的是过期值。
使用 volatile 修饰的变量,所有线程对它的读写操作都直接从主内存中进行,而不会使用线程的本地缓存,这保证了变量的可见性。
- 有序性
在 Java 中,编译器和 CPU 可能会对指令进行优化重排序,以提高性能。这种重排序可能会导致代码在多线程环境下产生意想不到的行为。
volatile 的作用:volatile 关键字禁止指令的重排序优化,保证对该变量的读写操作按程序的顺序执行,确保有序性。
- 不保证原子性
虽然 volatile 可以保证可见性和有序性,但它不保证原子性。如果多个线程同时对 volatile 变量执行复合操作(如递增),仍然会出现线程安全问题。
volatile 常见场景有以下两种:
状态标记
单例模式中的双重检查锁
我们在单例模式中使用 volatile,主要是使用 volatile 可以禁止指令重排序,从而保证程序的正常运行。这里可能会有读者提出疑问,不是已经使用了 synchronized 来保证线程安全吗?那为什么还要再加 volatile 呢?看下面的代码:
public class Singleton {
private Singleton() {}
// 使用 volatile 禁止指令重排序
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) { // ①
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // ②
}
}
}
return instance;
}
}注意观察上述代码,我标记了第 ① 处和第 ② 处的两行代码。给私有变量加 volatile 主要是为了防止第 ② 处执行时,也就是“instance = new Singleton()”执行时的指令重排序的,这行代码看似只是一个创建对象的过程,然而它的实际执行却分为以下 3 步:
创建内存空间。
在内存空间中初始化对象 Singleton。
将内存地址赋值给 instance 对象(执行了此步骤,instance 就不等于 null 了)。
试想一下,如果不加 volatile,那么线程 1 在执行到上述代码的第 ② 处时就可能会执行指令重排序,将原本是 1、2、3 的执行顺序,重排为 1、3、2。但是特殊情况下,线程 1 在执行完第 3 步之后,如果来了线程 2 执行到上述代码的第 ① 处,判断 instance 对象已经不为 null,但此时线程 1 还未将对象实例化完,那么线程 2 将会得到一个被实例化“一半”的对象,从而导致程序执行出错,这就是为什么要给私有变量添加 volatile 的原因了。
i++不是线程安全的:
i++需要基本的三个步骤:
1、读取 i 的当前值;
2、对 i 值进行加 1 操作;
3、将 i 值写回内存;
如果是方法里定义的,一定是线程安全的,因为本地方法栈是线程私有的;如果是类的静态成员变量或者用volatile修饰,i++则不是线程安全的,因为方法区和主内存是线程共享的。只能加锁 :sychronized关键字
线程间有哪些通信方式
Java 中线程之间的通信主要是为了解决线程之间如何协作运行的问题。
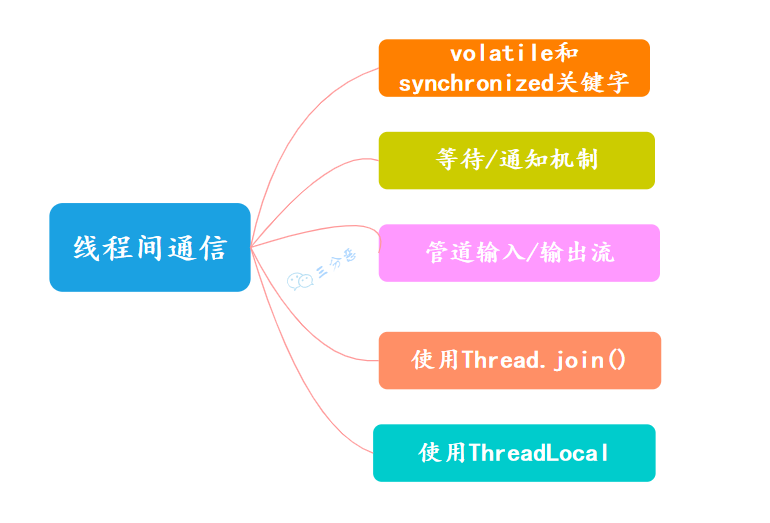
①、volatile 和 synchronized 关键字
volatile用来修饰成员变量,告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,保证所有线程对变量访问的可见性。
synchronized可以修饰方法,或者以同步代码块的形式来使用,确保多个线程在同一个时刻,只能有一个线程在执行某个方法或某个代码块。
②、等待/通知机制
一个线程调用共享对象的 wait() 方法时,它会进入该对象的等待池,并释放已经持有的该对象的锁,进入等待状态,直到其他线程调用相同对象的 notify() 或 notifyAll() 方法。
一个线程调用共享对象的 notify() 方法时,它会唤醒在该对象等待池中等待的一个线程,使其进入锁池,等待获取锁。
③、ThreadLocal
ThreadLocal 是什么?
ThreadLocal 是 Java 中提供的一种用于实现线程局部变量的工具类。就是每个线程都可以拥有自己的独立副本,从而实现线程隔离,用于解决多线程中共享对象的线程安全问题
你在工作中用到过 ThreadLocal 吗?
有用到过的,用来存储用户信息。
登录后的用户每次访问接口,都会在请求头中携带一个 token,在控制层拦截请求,根据这个 token判断用户是否存在,然后解析出用户的基本信息,然后把用户信息存入 ThreadLocal。这样在任何一个地方,都可以取出 ThreadLocal 中存的用户信息。
ThreadLocal 原理?
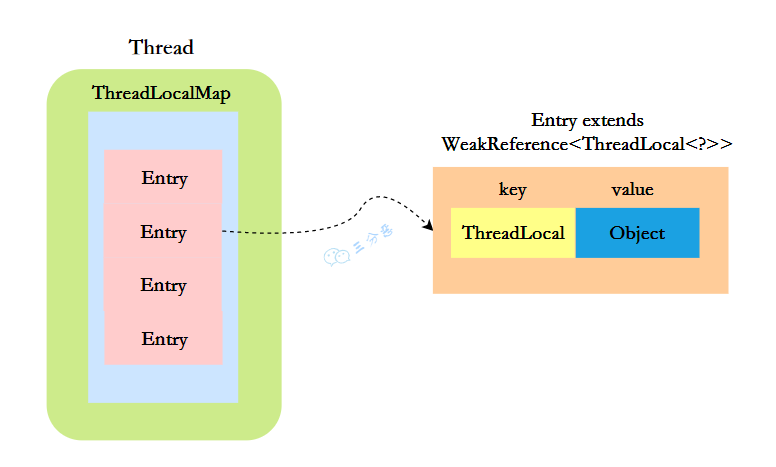
每个线程都有一个属于自己的 ThreadLocalMap。
ThreadLocalMap 内部,key 是 ThreadLocal 的弱引用,value 是 ThreadLocal 的泛型值。
每个线程在往 ThreadLocal 里设置值的时候,都是往自己的 ThreadLocalMap 里存,读也是以某个 ThreadLocal 作为引用,在自己的 map 里找对应的 key,从而实现了线程隔离。
ThreadLocal 本身不存储值,它只是作为一个 key 来让线程往 ThreadLocalMap 里存取值
什么是线程池?
线程池,简单来说,就是一个管理线程的池子。
①、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
②、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
③、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
工作中线程池的应用
- 异步下单的时候
- 逻辑过期解决缓存击穿,缓存重建(查询场馆信息时)

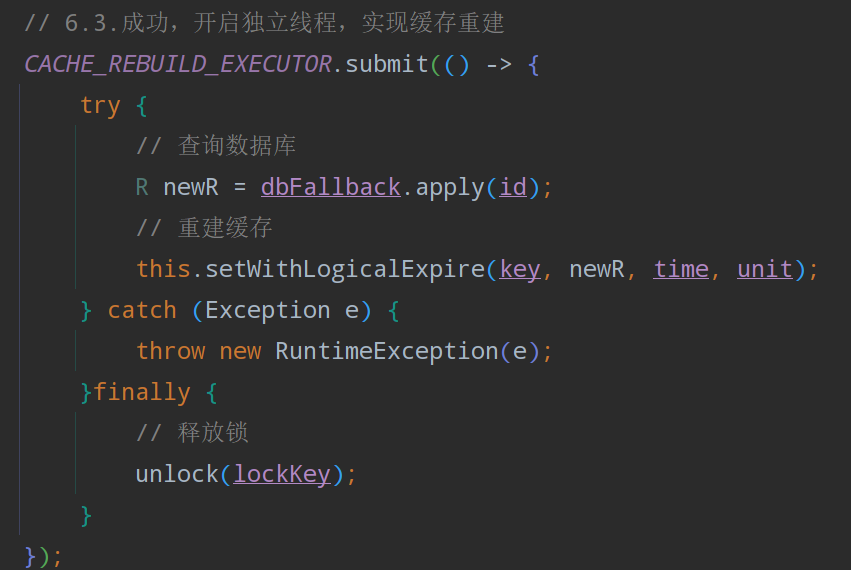
创建线程以及线程池主要参数有哪些?
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
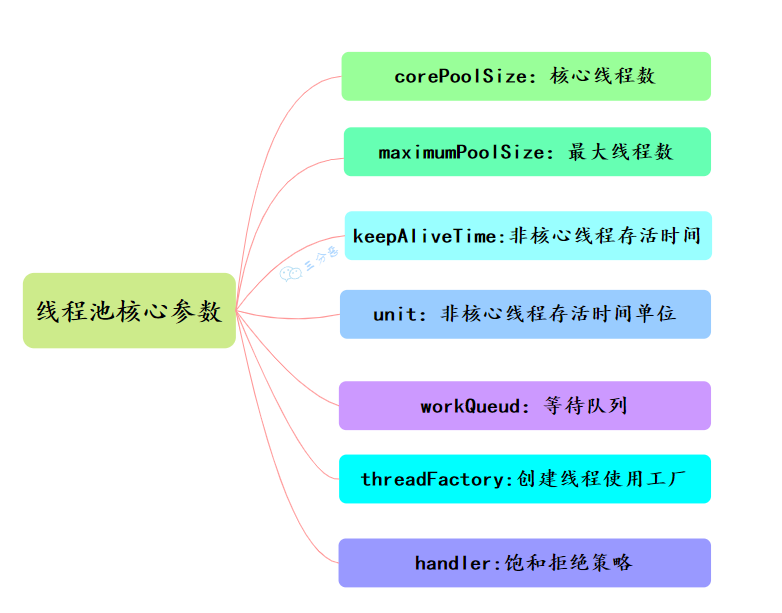
threadFactory));线程池有 7 个参数,需要重点关注corePoolSize、maximumPoolSize、workQueue、handler 这四个。
线程池参数
①、corePoolSize
定义了线程池中的核心线程数量。即使这些线程处于空闲状态,它们也不会被回收。这是线程池保持在等待状态下的线程数。
②、maximumPoolSize
线程池允许的最大线程数量。当工作队列满了之后,线程池会创建新线程来处理任务,直到线程数达到这个最大值。
③、keepAliveTime
非核心线程的空闲存活时间。如果线程池中的线程数量超过了 corePoolSize,那么这些多余的线程在空闲时间超过 keepAliveTime 时会被终止。
④、unit
keepAliveTime 参数的时间单位
⑤、workQueue
用于存放待处理任务的阻塞队列。当所有核心线程都忙时,新任务会被放在这个队列里等待执行。
⑥、threadFactory
一个创建新线程的工厂。它用于创建线程池中的线程。可以通过自定义 ThreadFactory 来给线程池中的线程设置有意义的名字,或设置优先级等。
⑦、handler
拒绝策略 RejectedExecutionHandler,定义了当线程池和工作队列都满了之后对新提交的任务的处理策略。常见的拒绝策略包括抛出异常、直接丢弃、丢弃队列中最老的任务、由提交任务的线程来直接执行任务等。
线程池的工作流程
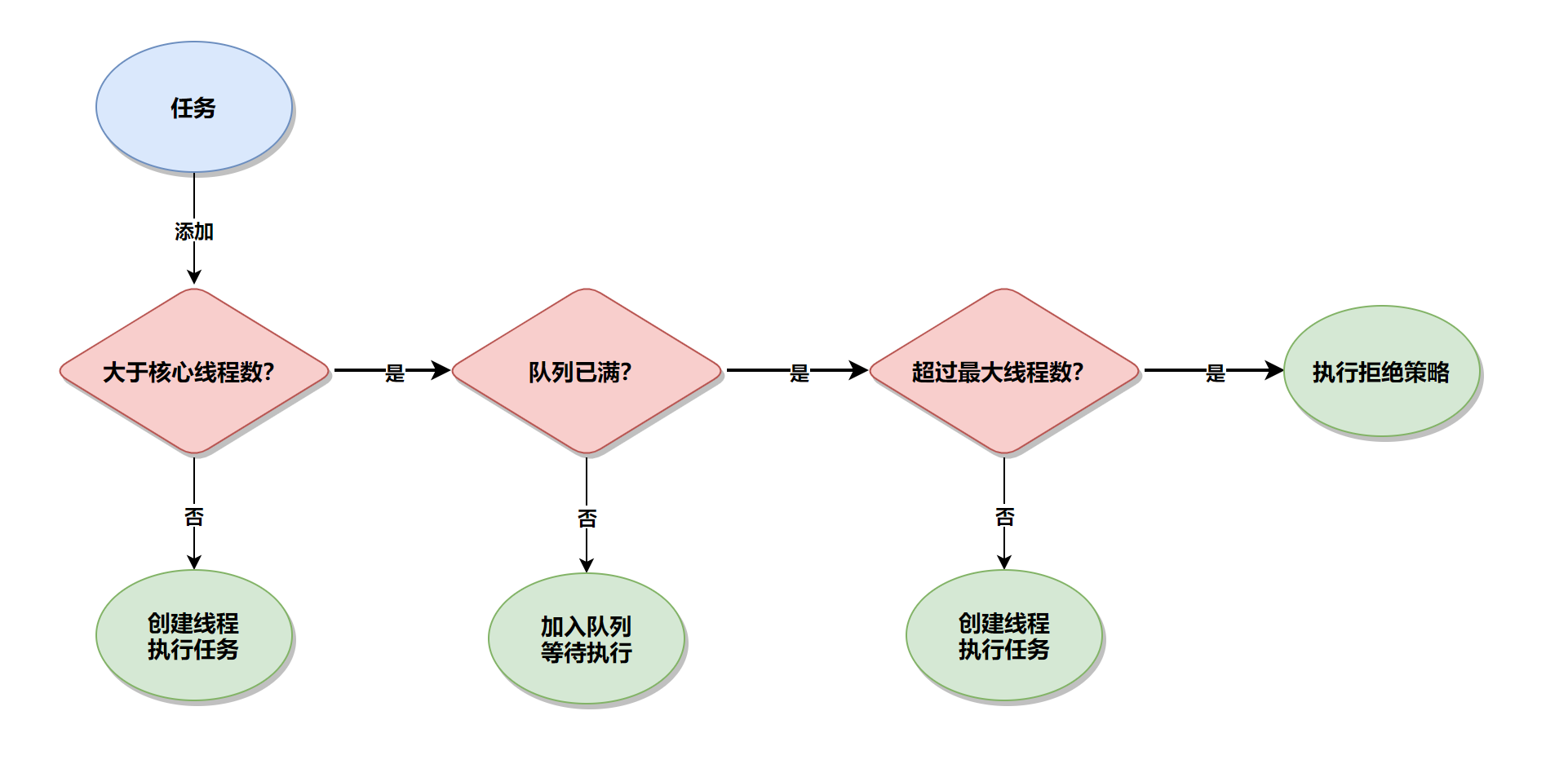
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会根据拒绝策略来对应处理。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小
当核心线程数为 0 时,当来了一个任务之后,会先将任务添加到任务队列,同时也会判断当前工作的线程数是否为 0,如果为 0,则会创建线程来执行线程池的任务
线程池提交 execute 和 submit 有什么区别?
execute 用于提交不需要返回值的任务
// 实现 Runnable接口,重写run方法
threadsPool.execute(new Runnable() {
@Override public void run() {
// TODO Auto-generated method stub }
});
threadPool.execute(() -> {
System.out.println(index + " 被执行,线程名:" + Thread.currentThread().getName());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});submit()方法用于提交需要返回值的任务。线程池会返回一个 future 类型的对象,通过这个 future 对象可以判断任务是否执行成功,并且可以通过 future 的 get()方法来获取返回值
Future<Object> future = executor.submit(harReturnValuetask);
try { Object s = future.get(); } catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池 executor.shutdown();
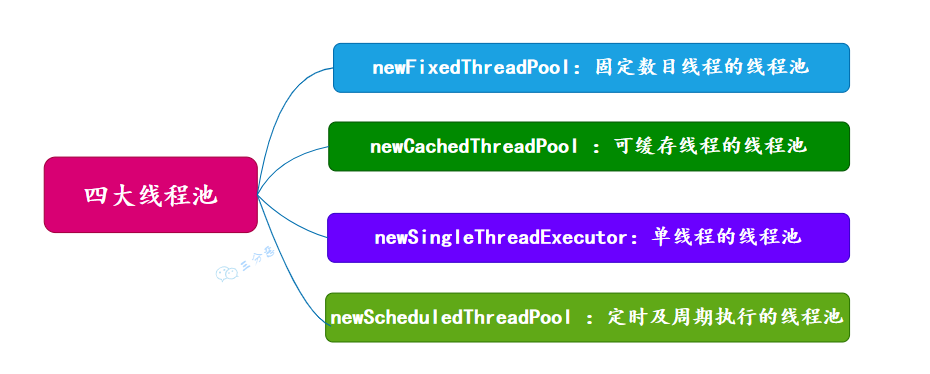
}有哪几种常见的线程池?
面试常问,主要有四种,都是通过工具类 Excutors 创建出来的

CAS 自旋锁
什么是CAS机制(compare and swap)
CAS算法的作用:解决多线程条件下使用锁造成性能损耗问题的算法,保证了原子性,这个原子操作是由CPU来完成的。
CAS的原理:CAS算法有三个操作数,通过内存中的值(V)、预期原始值(A)、修改后的新值。
(1)如果内存中的值和预期原始值相等, 就将修改后的新值保存到内存中。
(2)如果内存中的值和预期原始值不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作,直到重试成功。
- CAS基于乐观锁思想来设计的,其不会引发阻塞,synchronize会导致阻塞。
CAS的开销为什么比互斥锁轻量级
自旋锁在等待锁释放时不会使线程进入睡眠状态,而是让线程在一个循环中等待,直到获取到锁为止。这种方式避免了线程上下文切换的开销。
syncronized会阻塞线程,会进行线程的上下文切换,会由用户态切换到内核态,切换前需要保存用户态的上下文,而内核态恢复到用户态,又需要恢复保存的上下文,非常消耗资源。
CAS 有什么问题?如何解决?
CAS 的经典三大问题:
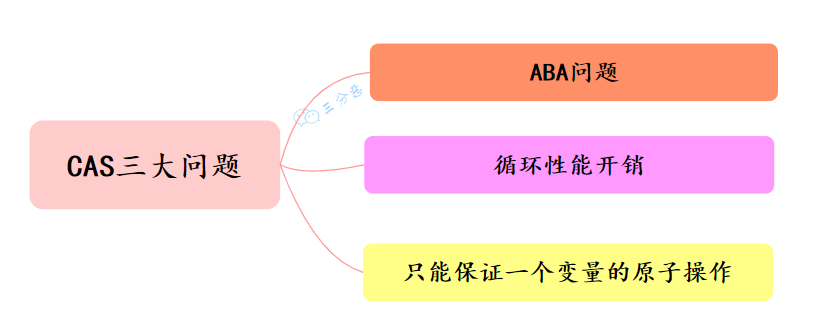
CAS三大问题
1. ABA 问题
并发环境下,假设初始条件是 A,去修改数据时,发现是 A 就会执行修改。但是看到的虽然是 A,中间可能发生了 A 变 B,B 又变回 A 的情况。此时 A 已经非彼 A,数据即使成功修改,也可能有问题。
怎么解决 ABA 问题?
- 加版本号
每次修改变量,都在这个变量的版本号上加 1,这样,刚刚 A->B->A,虽然 A 的值没变,但是它的版本号已经变了,再判断版本号就会发现此时的 A 已经被改过了。参考乐观锁的版本号,这种做法可以给数据带上了一种实效性的检验。
2. 循环性能开销
自旋 CAS,如果一直循环执行,一直不成功,会给 CPU 带来非常大的执行开销。
怎么解决循环性能开销问题?
在 Java 中,很多使用自旋 CAS 的地方,会有一个自旋次数的限制,超过一定次数,就停止自旋。
3. 只能保证一个变量的原子操作
CAS 保证的是对一个共享变量执行操作的原子性,如果对多个变量操作时,CAS 目前无法直接保证操作的原子性的。
怎么解决只能保证一个变量的原子操作问题?
可以考虑改用锁来保证操作的原子性
从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作
读写锁
针对这种读多写少的情况,Java 提供了另外一个实现 Lock 接口的 ReentrantReadWriteLock——读写锁。
读写锁允许同一时刻被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。
为什么读加锁
读锁是防止读到写的中间值。读锁在释放前,别的用户得不到相同资源的写锁。如果允许同时读和写,那读到的数很可能是就是写操作的中间状态。
synchronized
确保多个线程在同一个时刻,只能有一个线程在执行某个方法或某个代码块。
当 synchronized 修饰普通方法时,被修饰的方法被称为同步方法,其作用范围是整个方法,作用的对象是调用这个方法的对象。
当 synchronized 修饰静态的方法时,其作用的范围是整个方法,作用对象是调用这个类的所有对象。
为了减少锁的粒度,我们可以选择在一个方法中的某个部分使用 synchronized 来修饰(一段代码块),从而实现对一个方法中的部分代码进行加锁,实现代码如下:
public void classMethod() throws InterruptedException {
// 前置代码...
// 加锁代码
synchronized (SynchronizedExample.class) {
// ......
}
// 后置代码...
}以上代码在执行时,被修饰的代码块称为同步语句块,其作用范围是大括号“{}”括起来的代码块,作用的对象是调用这个代码块的对象。
synchronized锁 this 和锁 class
当使用 synchronized 加锁 class 时,无论共享一个对象还是创建多个对象,它们用的都是同一把锁;
而使用 synchronized 加锁 this 时,只有同一个对象会使用同一把锁,不同对象之间的锁是不同的。
import java.util.Date;
import java.util.concurrent.TimeUnit;
public class SynchronizedExample {
public static void main(String[] args) {
// 创建当前类实例(同一个锁对象)
// final SynchronizedExample example = new SynchronizedExample();
// 创建 5 个线程执行任务
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
// 创建(多个)类实例(不同锁对象)
SynchronizedExample example = new SynchronizedExample();
// 调用 synchronized 修饰的 this 方法
example.thisMethod();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
/**
* synchronized 修饰的 this 方法
* @throws InterruptedException
*/
public void thisMethod() throws InterruptedException {
synchronized (this) {
System.out.println(String.format("当前执行线程:%s,执行时间:%s",
Thread.currentThread().getName(), new Date()));
TimeUnit.SECONDS.sleep(1);
}
}
}线程死锁了解吗?该如何避免?
死锁发生在多个线程相互等待对方释放锁资源,导致所有线程都无法继续执行。
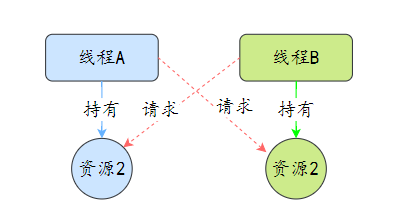
三分恶面渣逆袭:死锁示意图
为什么会产生死锁呢?
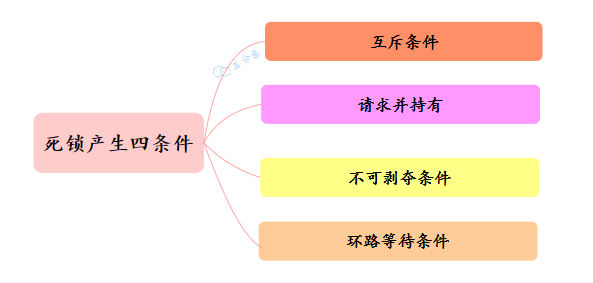
三分恶面渣逆袭:死锁产生必备四条件
互斥条件:资源不能被多个线程共享,一次只能由一个线程使用。如果一个线程已经占用了一个资源,其他请求该资源的线程必须等待,直到资源被释放。
持有并等待条件:一个线程至少已经持有至少一个资源,且正在等待获取额外的资源,这些额外的资源被其他线程占有。
不可剥夺条件:资源不能被强制从一个线程中抢占过来,只能由持有资源的线程主动释放。
循环等待条件:存在一种线程资源的循环链,每个线程至少持有一个其他线程所需要的资源,然后又等待下一个线程所占有的资源。这形成了一个循环等待的环路。
该如何避免死锁呢?
理解产生死锁的这四个必要条件后,就可以采取相应的措施来避免死锁,换句话说,就是至少破坏死锁发生的一个条件。
破坏互斥条件:这通常不可行,因为加锁就是为了互斥。
破坏持有并等待条件:一种方法是要求线程在开始执行前一次性地申请所有需要的资源。
破坏非抢占条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
破坏循环等待条件:对所有资源类型进行排序,强制每个线程按顺序申请资源,这样可以避免循环等待的发生。
那死锁问题怎么排查呢?
首先从系统级别上排查,比如说在 Linux 生产环境中,可以先使用 top ps 等命令查看进程状态,看看是否有进程占用了过多的资源。
接着,使用 JDK 自带的一些性能监控工具进行排查,比如说,使用 jps -l 查看当前 Java 进程,然后使用 jstack 进程号 查看当前 Java 进程的线程堆栈信息,看看是否有线程在等待锁资源。
// 死锁的例子
class DeadLockDemo {
private static final Object lock1 = new Object();
private static final Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
System.out.println("线程1获取到了锁1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
System.out.println("线程1获取到了锁2");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
System.out.println("线程2获取到了锁2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
System.out.println("线程2获取到了锁1");
}
}
}).start();
}
}