MyBatis-Plus
MyBatis-Plus实体类注解
- @TableName("表名")
- @TableId(表名主键)
value:主键字段名
type:主键类型:
写法:IdType.NONE\- AUTO——数据库自增
- INPUT——自行输入
- ID_WORKER——分布式全局唯一ID长整型类型
- UUID——32位UUID字符串
- NONE——无状态
- ID_WORKER_STR——分布式全局唯一ID字符串类型
@TableId(value = “id”, type = IdType.AUTO):自增@TableId(value = “id”, type = IdType.ID_WORKER_STR):分布式全局唯一ID字符串类型@TableId(value = “id”, type = IdType.INPUT):自行输入@TableId(value = “id”, type = IdType.ID_WORKER):分布式全局唯一ID 长整型类型@TableId(value = “id”, type = IdType.UUID):32位UUID字符串@TableId(value = “id”, type = IdType.NONE):无状态
- @TableField
value:字段名
exit:是否为数据库表字段
Strategy:字段验证@TableField(value = “age”): 用来解决数据库中的字段和实体类的字段不匹配问题@TableField(exist = false): 用来解决实体类中有的属性但是数据表中没有的字段,默认为true@TableField(condition = SqlCondition.LIKE):表示该属性可以模糊搜索。@TableField(fill = FieldFill.INSERT):注解填充字段 ,生成器策略部分也可以配置
Mybatis-Plus CRUD 操作
Mapper 接口方法(CRUD)
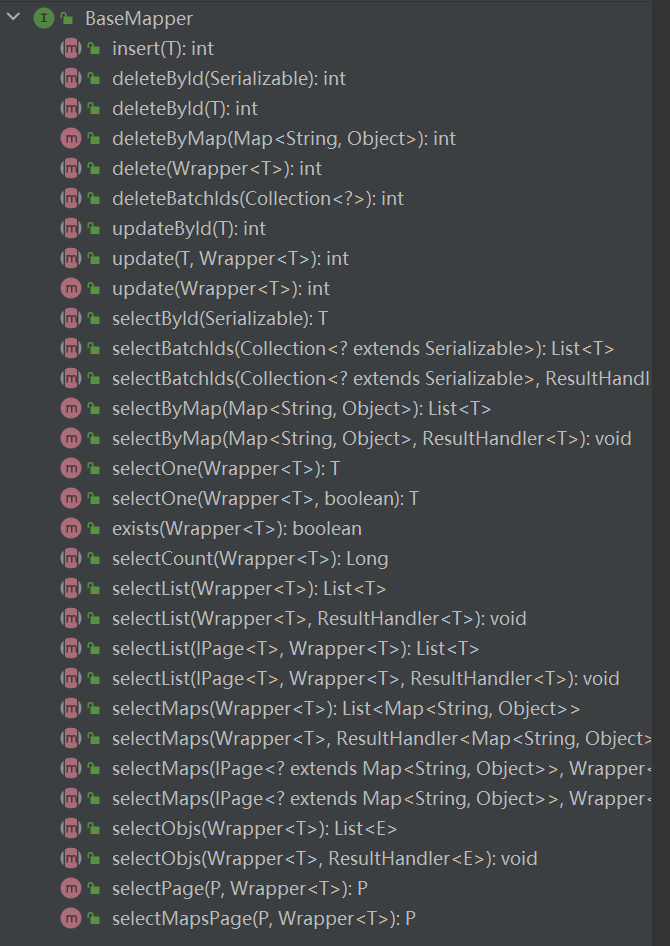
使用代码生成器生成的 mapper 接口中,其继承了 BaseMapper 接口。而 BaseMapper 接口中封装了一系列 CRUD 常用操作,可以直接使用,而不用自定义 xml 与 sql 语句进行 CRUD 操作(当然根据实际开发需要,自定义 sql 还是有必要的)。
java
public interface BookMapper extends BaseMapper<Book> {
}
java
【添加数据:(增)】
int insert(T entity); // 插入一条记录
注:
T 表示任意实体类型
entity 表示实体对象
【删除数据:(删)】
int deleteById(Serializable id); // 根据主键 ID 删除
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据 map 定义字段的条件删除
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper); // 根据实体类定义的 条件删除对象
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量删除
注:
id 表示 主键 ID
columnMap 表示表字段的 map 对象
wrapper 表示实体对象封装操作类,可以为 null。
idList 表示 主键 ID 集合(列表、数组),不能为 null 或 empty
【修改数据:(改)】
int updateById(@Param(Constants.ENTITY) T entity); // 根据 ID 修改实体对象。
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper); // 根据 updateWrapper 条件修改实体对象
注:
update 中的 entity 为 set 条件,可以为 null。
updateWrapper 表示实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
【查询数据:(查)】
T selectById(Serializable id); // 根据 主键 ID 查询数据
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量查询
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据表字段条件查询
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 根据实体类封装对象 查询一条记录
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询记录的总条数
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合)
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合)
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(但只保存第一个字段的值)
<E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 entity 集合),分页
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper); // 查询所有记录(返回 map 集合),分页
注:
queryWrapper 表示实体对象封装操作类(可以为 null)
page 表示分页查询条件Service 接口方法(CRUD)
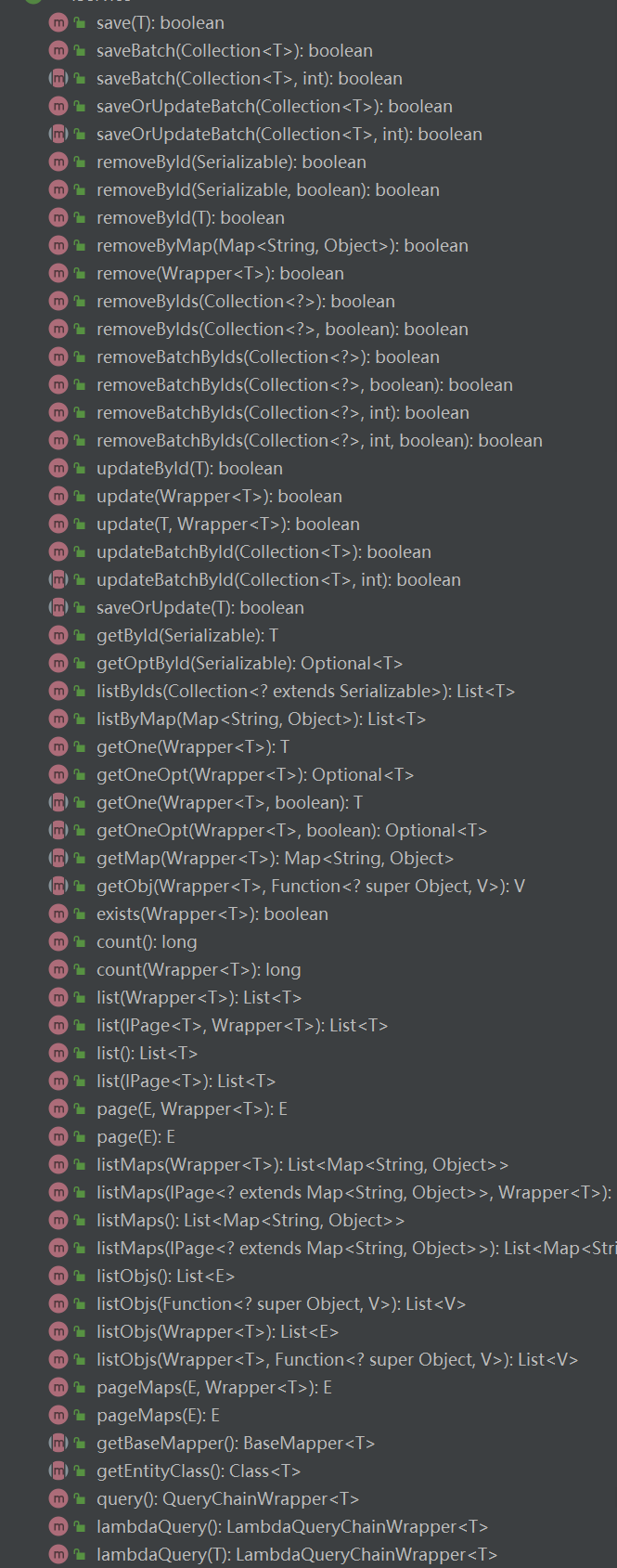
使用 代码生成器 生成的 service 接口中,其继承了 IService 接口。IService 内部进一步封装了 BaseMapper 接口的方法(当然也提供了更详细的方法)。使用时,可以通过生成的 mapper 接口进行 CRUD 操作,也可以通过生成的 service 接口的实现类进行 CRUD 操作。
java
public interface IBookService extends IService<Book> {
}
java
【添加数据:(增)】
default boolean save(T entity); // 调用 BaseMapper 的 insert 方法,用于添加一条数据。
boolean saveBatch(Collection<T> entityList, int batchSize); // 批量插入数据
注:
entityList 表示实体对象集合
batchSize 表示一次批量插入的数据量,默认为 1000
【添加或修改数据:(增或改)】
boolean saveOrUpdate(T entity); // id 若存在,则修改, id 不存在则新增数据
default boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 先根据条件尝试更新,然后再执行 saveOrUpdate 操作
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize); // 批量插入并修改数据
【删除数据:(删)】
default boolean removeById(Serializable id); // 调用 BaseMapper 的 deleteById 方法,根据 id 删除数据。
default boolean removeByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 deleteByMap 方法,根据 map 定义字段的条件删除
default boolean remove(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 delete 方法,根据实体类定义的 条件删除对象。
default boolean removeByIds(Collection<? extends Serializable> idList); // 用 BaseMapper 的 deleteBatchIds 方法, 进行批量删除。
【修改数据:(改)】
default boolean updateById(T entity); // 调用 BaseMapper 的 updateById 方法,根据 ID 选择修改。
default boolean update(T entity, Wrapper<T> updateWrapper); // 调用 BaseMapper 的 update 方法,根据 updateWrapper 条件修改实体对象。
boolean updateBatchById(Collection<T> entityList, int batchSize); // 批量更新数据
【查找数据:(查)】
default T getById(Serializable id); // 调用 BaseMapper 的 selectById 方法,根据 主键 ID 返回数据。
default List<T> listByIds(Collection<? extends Serializable> idList); // 调用 BaseMapper 的 selectBatchIds 方法,批量查询数据。
default List<T> listByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 selectByMap 方法,根据表字段条件查询
default T getOne(Wrapper<T> queryWrapper); // 返回一条记录(实体类保存)。
Map<String, Object> getMap(Wrapper<T> queryWrapper); // 返回一条记录(map 保存)。
default int count(Wrapper<T> queryWrapper); // 根据条件返回 记录数。
default List<T> list(); // 返回所有数据。
default List<T> list(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectList 方法,查询所有记录(返回 entity 集合)。
default List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMaps 方法,查询所有记录(返回 map 集合)。
default List<Object> listObjs(); // 返回全部记录,但只返回第一个字段的值。
default <E extends IPage<T>> E page(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectPage 方法,分页查询
default <E extends IPage<Map<String, Object>>> E pageMaps(E page, Wrapper<T> queryWrapper); // 调用 BaseMapper 的 selectMapsPage 方法,分页查询
注:
get 用于返回一条记录。
list 用于返回多条记录。
count 用于返回记录总数。
page 用于分页查询。
【链式调用:】
default QueryChainWrapper<T> query(); // 普通链式查询
default LambdaQueryChainWrapper<T> lambdaQuery(); // 支持 Lambda 表达式的修改
default UpdateChainWrapper<T> update(); // 普通链式修改
default LambdaUpdateChainWrapper<T> lambdaUpdate(); // 支持 Lambda 表达式的修改
注:
query 表示查询
update 表示修改
Lambda 表示内部支持 Lambda 写法。
形如:
query().eq("column", value).one();
lambdaQuery().eq(Entity::getId, value).list();
update().eq("column", value).remove();
lambdaUpdate().eq(Entity::getId, value).update(entity);条件构造器(Wrapper,定义 where 条件)
上面介绍的接口方法的参数中,会出现各种 wrapper,比如 queryWrapper、updateWrapper 等。wrapper 的作用就是用于定义各种各样的查询条件(where)。
java
【通用条件:】
【比较大小: ( =, <>, >, >=, <, <= )】
eq(R column, Object val); // 等价于 =,例: eq("name", "老王") ---> name = '老王'
ne(R column, Object val); // 等价于 <>,例: ne("name", "老王") ---> name <> '老王'
gt(R column, Object val); // 等价于 >,例: gt("name", "老王") ---> name > '老王'
ge(R column, Object val); // 等价于 >=,例: ge("name", "老王") ---> name >= '老王'
lt(R column, Object val); // 等价于 <,例: lt("name", "老王") ---> name < '老王'
le(R column, Object val); // 等价于 <=,例: le("name", "老王") ---> name <= '老王'
【范围:(between、not between、in、not in)】
between(R column, Object val1, Object val2); // 等价于 between a and b, 例: between("age", 18, 30) ---> age between 18 and 30
notBetween(R column, Object val1, Object val2); // 等价于 not between a and b, 例: notBetween("age", 18, 30) ---> age not between 18 and 30
in(R column, Object... values); // 等价于 字段 IN (v0, v1, ...),例: in("age",{1,2,3}) ---> age in (1,2,3)
notIn(R column, Object... values); // 等价于 字段 NOT IN (v0, v1, ...), 例: notIn("age",{1,2,3}) ---> age not in (1,2,3)
inSql(R column, Object... values); // 等价于 字段 IN (sql 语句), 例: inSql("id", "select id from table where id < 3") ---> id in (select id from table where id < 3)
notInSql(R column, Object... values); // 等价于 字段 NOT IN (sql 语句)
【模糊匹配:(like)】
like(R column, Object val); // 等价于 LIKE '%值%',例: like("name", "王") ---> name like '%王%'
notLike(R column, Object val); // 等价于 NOT LIKE '%值%',例: notLike("name", "王") ---> name not like '%王%'
likeLeft(R column, Object val); // 等价于 LIKE '%值',例: likeLeft("name", "王") ---> name like '%王'
likeRight(R column, Object val); // 等价于 LIKE '值%',例: likeRight("name", "王") ---> name like '王%'
【空值比较:(isNull、isNotNull)】
isNull(R column); // 等价于 IS NULL,例: isNull("name") ---> name is null
isNotNull(R column); // 等价于 IS NOT NULL,例: isNotNull("name") ---> name is not null
【分组、排序:(group、having、order)】
groupBy(R... columns); // 等价于 GROUP BY 字段, ..., 例: groupBy("id", "name") ---> group by id,name
orderByAsc(R... columns); // 等价于 ORDER BY 字段, ... ASC, 例: orderByAsc("id", "name") ---> order by id ASC,name ASC
orderByDesc(R... columns); // 等价于 ORDER BY 字段, ... DESC, 例: orderByDesc("id", "name") ---> order by id DESC,name DESC
having(String sqlHaving, Object... params); // 等价于 HAVING ( sql语句 ), 例: having("sum(age) > {0}", 11) ---> having sum(age) > 11
【拼接、嵌套 sql:(or、and、nested、apply)】
or(); // 等价于 a or b, 例:eq("id",1).or().eq("name","老王") ---> id = 1 or name = '老王'
or(Consumer<Param> consumer); // 等价于 or(a or/and b),or 嵌套。例: or(i -> i.eq("name", "李白").ne("status", "活着")) ---> or (name = '李白' and status <> '活着')
and(Consumer<Param> consumer); // 等价于 and(a or/and b),and 嵌套。例: and(i -> i.eq("name", "李白").ne("status", "活着")) ---> and (name = '李白' and status <> '活着')
nested(Consumer<Param> consumer); // 等价于 (a or/and b),普通嵌套。例: nested(i -> i.eq("name", "李白").ne("status", "活着")) ---> (name = '李白' and status <> '活着')
apply(String applySql, Object... params); // 拼接sql(若不使用 params 参数,可能存在 sql 注入),例: apply("date_format(dateColumn,'%Y-%m-%d') = {0}", "2008-08-08") ---> date_format(dateColumn,'%Y-%m-%d') = '2008-08-08'")
last(String lastSql); // 无视优化规则直接拼接到 sql 的最后,可能存若在 sql 注入。
exists(String existsSql); // 拼接 exists 语句。例: exists("select id from table where age = 1") ---> exists (select id from table where age = 1)
【QueryWrapper 条件:】
select(String... sqlSelect); // 用于定义需要返回的字段。例: select("id", "name", "age") ---> select id, name, age
select(Predicate<TableFieldInfo> predicate); // Lambda 表达式,过滤需要的字段。
lambda(); // 返回一个 LambdaQueryWrapper
【UpdateWrapper 条件:】
set(String column, Object val); // 用于设置 set 字段值。例: set("name", null) ---> set name = null
etSql(String sql); // 用于设置 set 字段值。例: setSql("name = '老李头'") ---> set name = '老李头'
lambda(); // 返回一个 LambdaUpdateWrapper简单测试
java
@Test
public void testQueryWrapper() {
// Step1:创建一个 QueryWrapper 对象
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// Step2: 构造查询条件
queryWrapper
.select("id", "name", "age")
.eq("age", 20)
.like("name", "sun");
// SELECT id, name, age FROM table WHERE age = 20 AND name like %sun%;
// Step3:执行查询
userService
.list(queryWrapper)
.forEach(System.out::println);
}