RabbitMQ
为什么要使用消息队列呢?
消息队列主要有三大用途,我们拿一个电商系统的下单举例:
解耦:用户下单后可以把订单完成的消息丢进队列里,这样就完成了用户下单和记录到数据库的解耦。
异步:下单之后,我们要扣减库存、增加积分、发送消息等等,这样一来这个链路就长了,链路一长,响应时间就变长了。引入消息队列,除了
更新订单状态,其它的都可以异步去做,这样一来就来,就能降低响应时间。削峰:消息队列可以用来削峰,例如秒杀系统,平时流量很低,但是要做秒杀活动,秒杀的时候流量疯狂怼进来,我们的服务器,Redis,MySQL各自的承受能力都不一样,直接全部流量照单全收肯定有问题啊,严重点可能直接打挂了。我们可以把请求扔到队列里面,这样就能抗住短时间的大流量了。
解耦、异步、削峰,是消息队列最主要的三大作用
什么是消息队列
消息队列是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。
参与消息传递的双方称为 生产者 和 消费者 ,生产者负责发送消息,消费者负责处理消息。
RabbitMQ 的整体模型架构如下:
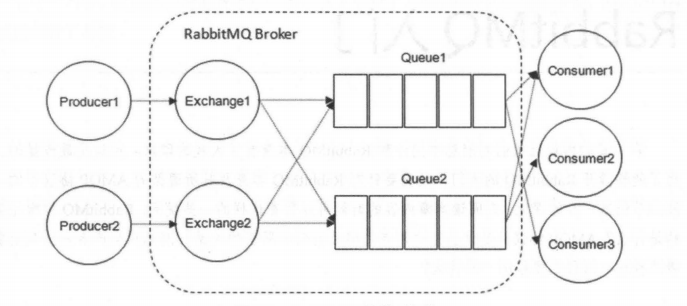
RabbitMQ 的整体模型架构
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
说说生产者 Producer 和消费者 Consumer?
生产者 :
消息生产者,就是投递消息的一方。
消息一般包含两个部分:消息体(
payload)和标签(Label)。
消费者:
消费消息,也就是接收消息的一方。
消费者连接到 RabbitMQ 服务器,并订阅到队列上。消费消息时只消费消息体,丢弃标签。
说说 Broker 服务节点、Queue 队列、Exchange 交换器?
Broker:可以看做 RabbitMQ 的服务节点。一般情况下一个 Broker 可以看做一个 RabbitMQ 服务器。
Queue:RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
Exchange:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
RabbitMQ 消息怎么传输?
由于 TCP 链接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈
RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接,且每条 TCP 链接上的信道数量没有限制。就是说 RabbitMQ 在一条 TCP 链接上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个信道在 RabbitMQ 都有唯一的 ID,保证了信道私有性,每个信道对应一个线程使用。
如何保证消息的可靠性?

一、生产者到 RabbitMQ:
消息发送失败情况:
- 网络抖动导致生产者和mq之间的连接中断,导致消息都没发。
答:rabbitmq有自动重连机制,叫retry。可以通过设置retryTemplate来设置重连次数。
消息发了但是进入到交换机之前消息丢了。(如果开启了消息持久化,那则是持久化之前。交换机、队列、消息默认都是持久化的)
答:rabbitmq有confirm机制,即mq收到消息后会发送一个叫ack的标识给生产者,ack为true表示收到了,ack为false表示没收到或丢了。rabbitTemplate中有confirmCallback接口,在这个callback里把ack为false的消息存到缓存,用另外线程重发。
java@Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { String msgId = correlationData.getId(); if(ack){ //发送成功 logger.debug("ack,消息投递到exchange成功,msgId:{}",msgId); }else{ //发送失败,重试 logger.error("ack,消息投递exchange失败,msgId:{},原因{}" ,msgId, cause); } }消息到交换机了,但是找不到对应的queue。
答:rabbitmq有return机制,在rabbitTemplate中有returnCallback接口。找不到queue的消息都会进入到这个callback,通过实现ReturnCallback接口,对回退消息进行重发处理,在这个callback里把消息存到缓存,用另外线程重发。
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
logger.error("消息发送失败-消息回退,应答码:{},原因:{},交换机:{},路由键:{}", replyCode, replyText, exchange, routingKey);
String msgId = message.getMessageProperties().getCorrelationId();
String data = new String(message.getBody());
saveToDB(msgId, data, routingKey, "92");
}二、RabbitMQ 自身:持久化、集群(普通模式、镜像模式)
消息持久化:相关的数据都持久化到硬盘中。在Spring Boot中消息默认就是持久化的。

三、RabbitMQ 到消费者:
改为手动消费,当消息消费失败时,消费端回复nack,消息重新入队。
SpringBoot 给我们提供了一种重试机制,当消费者执行的业务方法报错时会重试执行消费者业务方法。
spring:
rabbitmq:
template:
retry:
enabled: true
max-attempts: 5 # 最大重试次数
initial-interval: 1000ms # 初始等待时间1秒
multiplier: 2.0 # 每次重试间隔时间倍增
max-interval: 10000ms # 最大等待时间10秒消息重试机制通常在以下情况下触发:
消费者处理消息失败或抛出异常。
消费者崩溃或与 RabbitMQ 连接中断。
消费者拒绝消息(NACK),并要求重新投递。
网络或通信异常导致消息未能确认。
镜像集群模式
RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
消息重复消费怎么处理?
消息重复的原因有两个:
- 生产时消息重复
生产者发送消息给MQ,在MQ确认的时候出现了网络波动,生产者没有收到确认,这时候生产者就会重新发送这条消息,导致MQ会接收到重复消息。
- 消费时消息重复。
消费者消费成功后,给MQ确认的时候出现了网络波动,MQ没有接收到确认,为了保证消息不丢失,MQ就会继续给消费者投递之前的消息。这时候消费者就接收到了两条一样的消息。
由于重复消息是由于网络原因造成的,无法避免。
解决方法:发送消息时让每个消息携带一个全局的唯一ID,在消费消息时先判断消息是否已经被消费过,保证消息消费逻辑的幂等性。具体消费过程为:
消费者获取到消息后先根据id去查询redis/db是否存在该消息
如果不存在,则正常消费,消费完毕后写入redis/db
如果存在,则证明消息被消费过,直接丢弃
避免消息积压问题
消息源头 生产者:
- 控制流量峰值(削峰)
可以通过限流和熔断机制来控制流量,避免瞬时流量峰值冲击。
限流策略:通过令牌桶或漏桶算法,在消息进入 RabbitMQ 之前进行限流,确保不会产生超出系统承载能力的消息。
熔断机制:在系统压力过大时,可以自动停止或延迟接受新的请求,防止消息队列进一步积压。
消费者:
提高消费者的并发和处理能力
- 增加消费者实例数: 如果消息积压,消费者处理能力不足,可以通过增加消费者实例的数量来提高并发处理能力。每个消费者实例可以同时处理多个消息,从而加速消息的消费速度。
RabbitMQ 并发消费者配置:可以调整 concurrency ( 最小消费者数量)和 max-concurrency (最大消费者数量)来增加消费者并发数量。
队列:
- 消息优先级队列
引入消息优先级机制: 可以根据消息的重要性和处理紧急度设置优先级,让更重要或更紧急的消息优先被处理,从而避免低优先级消息大量积压影响关键消息的处理。
- 合理设置消息TTL与死信队列
消息TTL(Time-to-Live): 设置消息的过期时间(TTL),让不需要处理的过期消息自动从队列中移除,防止过多无效消息占用队列空间。
死信队列(DLX): 当消息无法被消费(如超出重试次数、TTL过期等)时,可以将这些消息转移到死信队列进行集中处理,防止它们占用主队列的资源。
结合死信队列机制,将无法处理的消息丢到死信队列,并根据业务需求处理。
- 合理配置消息重试机制
限制重试次数与重试间隔: 通过合理配置 RabbitMQ 的消息重试机制,避免失败消息被无限次重试,导致队列进一步积压。可以控制重试的次数和重试的时间间隔。
硬件维护:
- 监控与预警
RabbitMQ 消息堆积监控: 设置监控系统,对 RabbitMQ 的队列积压情况进行实时监控。当消息积压到一定程度时,系统可以发出告警,以便运维人员及时处理。
可以使用 RabbitMQ 的管理插件(如 Prometheus + Grafana)来监控队列长度、消费者的处理速率等关键指标。
- 采用分布式消息队列
在极高并发的情况下,单一的 RabbitMQ 可能无法应对全部流量。可以通过分布式架构将流量分散到多个 RabbitMQ 实例上,采用分片机制来减少单个队列的压力。
结合如 Kafka 等分布式消息队列系统,可以应对超大规模的流量峰值。
- 提升RabbitMQ服务端性能
硬件优化: 增加 RabbitMQ 服务器的硬件资源,如 CPU、内存和磁盘 I/O 性能,确保 RabbitMQ 本身不会成为瓶颈。
集群模式: 通过设置 RabbitMQ 集群,分布消息的处理负载,提升整体处理能力。
磁盘队列优化: 通过 RabbitMQ 提供的磁盘队列,将消息持久化到磁盘,以防止内存耗尽,同时确保消息持久化的可靠性。
如何保证 RabbitMQ 消息的顺序性?
拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者)
或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理
什么是死信队列?
消费失败的消息存放的队列。
消息消费失败的原因:
消息被拒绝并且消息没有重新入队(requeue=false)
消息超时未消费
达到最大队列长度
导致的死信的几种原因?
消息被拒(Basic.Reject /Basic.Nack) 且 requeue = false。
消息TTL过期。
队列满了,无法再添加。